博亚体育 AI数据中心, 投资崩溃点在那边?


本文将基于GPU、HBM和电力成本,反向推算出“东谈主工智能数据中心投资的崩溃点”。
对东谈主工智能数据中心的投资显着已达到前所未有的水平。微软、谷歌、亚马逊和Meta等超大规模数据中心巨头竞相每年投资数千亿好意思元。据TrendForce预测,到2026年,这四大超大规模数据中心巨头的总投资额将高达7550亿好意思元(图1)。按1好意思元兑160日元的汇率盘算,这额外于约120.8万亿日元,高出了日本2025财年的国度预算(一般账户预算总和约为115万亿日元,数据来源:日本财务省)。
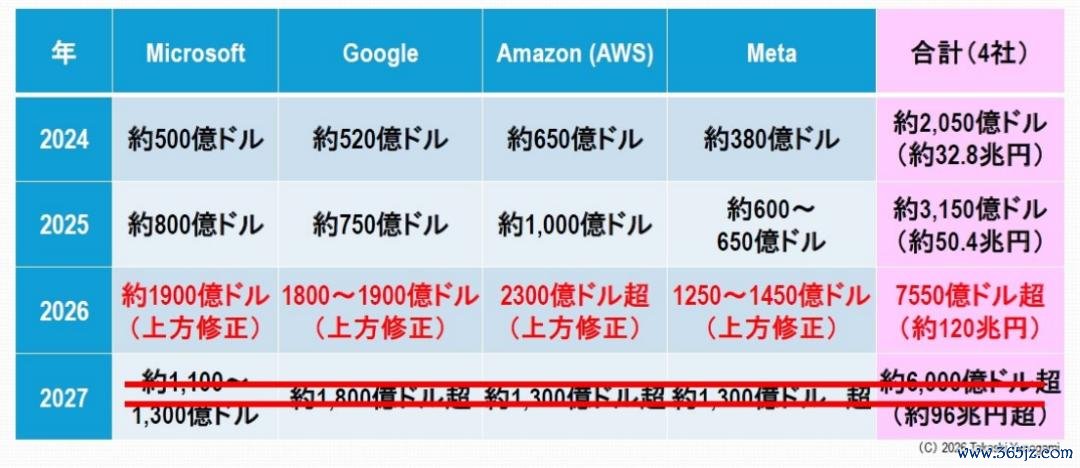
图1:前 4 大超大规模数据中心运营商对数据中心的荒诞老本投资
之是以需要如斯多数的投资,是因为东谈主工智能功绩器中使用的AI半导体价钱飞涨。以最初的AI半导体制造商NVIDIA的GPU为例,其咫尺的旗舰架构“Blackwell”中,单颗“B200”GPU的价钱在500万至800万日元之间,一台配备8颗B200 GPU的“DGX B200”功绩器的价钱在4000万至7000万日元之间,而基于该功绩器的AI机架的价钱则高达数亿至10亿日元(图2)。由于构建AI数据中心需要巨额部署这些AI机架,因此每个超大规模数据中心运营商的投资额都高出1000亿至2000亿好意思元。
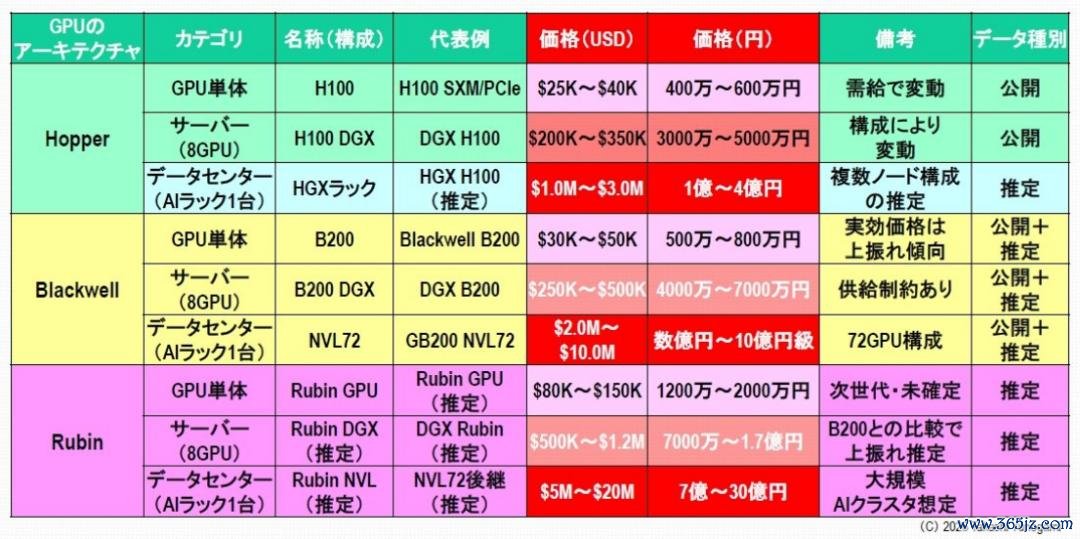
图2:NVIDIA GPU AI 功绩器和数据中心(Hopper、Blackwell、Rubin)的订价结构
可是,这还是超出了“增长投资”一词所能讲解的鸿沟,而更像是“为了竞争而进行的军事栽培”。
在这种情况下,有一个很少被平直参谋的要津问题:“这项投资的确不错收回成本吗?”固然东谈主工智能昂扬强调的是强劲的需乞降时间更动,但关于老本密集型行业来说,最终的问题是投资能否收回成本。
本文将东谈主工智能数据中心的成本结构理解为三个要素:GPU、宽带内存(HBM)和电力。此外,本文期骗微软和谷歌公开的实践数据,对现时东谈主工智能投资的收入结构进行了定量分析。基于此分析,本文试图估算“崩溃线”,即投资无法收回的临界点。
请防范,天职析侧重于GPU基础步伐按小时计费带来的直袭取入,并不包括东谈主工智能带来的波折收入(举例搜索告白质料升迁或SaaS价值增多)。阅读本文时,请铭刻这极少。
妄下雌黄地说,好意思国超大规模数据中心运营商在东谈主工智能数据中心看似荒诞的投资很可能还是注定失败。借用动漫《北斗神拳》中健次郎的一句名言:“你还是死了。”
从微软和谷歌的案例看投资规模的现实
图3以量化式样展示了微软和谷歌的实践投资规模。基于这些数据,它充分确认了微软和谷歌(Alphabet 的子公司)在数据中心领域的投资规模之弘大令东谈主凝视。
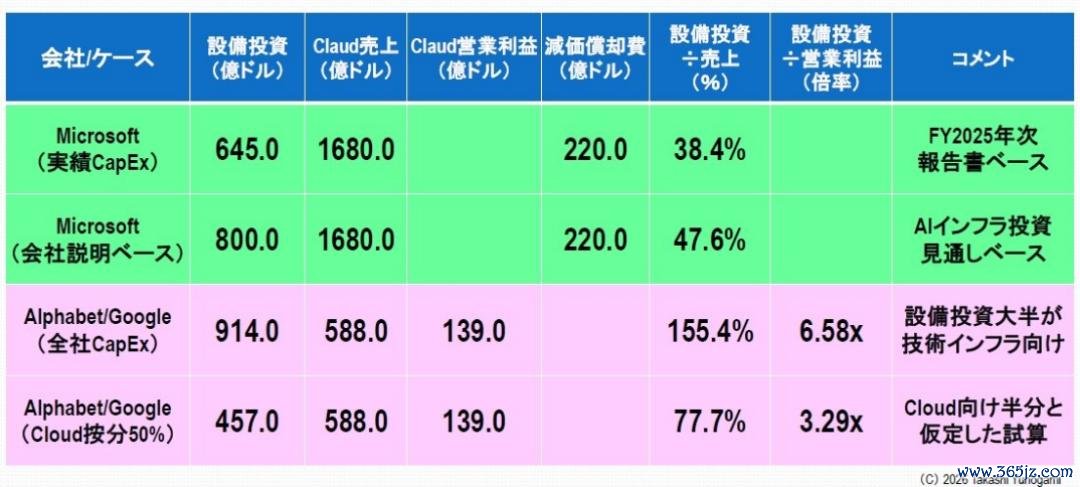
图3:微软和谷歌的实践投资规模
微软的案例
凭证微软2025财年年度陈诉,老本开销(不包括固定金钱和开采)预测将达到645亿好意思元。此外,该公司暗示,投资(主要用于东谈主工智能基础步伐)预测将高出800亿好意思元。
与微软云业务1680亿好意思元的营收比较,老本开销约占营收的38%,或凭证公司声明约为48%。往往情况下,在褂讪的基础步伐业务中,老本开销很少高出营收的30%,因此这一比例极其荒僻。
更热切的是,折旧用度已达220亿好意思元。这意味着夙昔的投资包袱还是源泉影响公司的损益,况且这种包袱在将来几年可能会不绝增多。此外,如上图1所示,微软2026年的老本开销预测将达到1900亿好意思元,约为上年的2.4倍。因此,微软的利润和耗损预测将大幅下降。
谷歌的案例
与此同期,谷歌母公司Alphabet正在进行更大规模的投资。其2025年的老本开销达到914亿好意思元,其中大部分将用于功绩器和数据中心等时间基础步伐。比较之下,谷歌云的年收入约为588亿好意思元,交易利润约为139亿好意思元。
开云体育中国官网在线入口天然,这914亿好意思元的老本开销不仅相沿云盘算业务,也相沿公司范围内的基础步伐,举例搜索引擎和东谈主工智能议论平台。可是,即使其中一半用于云盘算功绩,也仍然高达约457亿好意思元,约占云盘算销售额的80%,约为交易利润的3.3倍。即便推敲到这极少,显着咫尺的投资规模与传统的陈诉格式存在权贵偏差。
此外,与微软不异,谷歌2026年的举座老本开销预测将达到1800亿至1900亿好意思元,约为上一年的2.4至2.5倍。鉴于如斯高的老本开销水平,不难念念象,收回对云盘算业务的投资将变得愈加认真。
东谈主工智能数据中心的成本结构
这项多数投资的原因在于东谈主工智能数据中心独到的成本结构。起先,咱们将估算东谈主工智能数据中心的成本结构和市集范围(图4)。
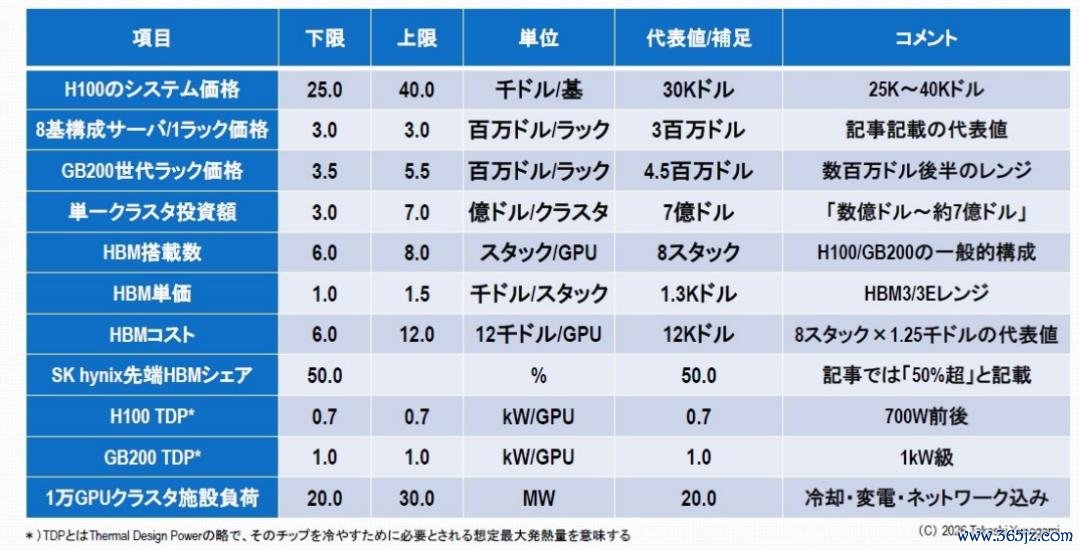
图4:AI 数据中心的成本结构和市集范围
起先,咱们来望望GPU。咫尺的AI基础步伐实在全都依赖于NVIDIA的GPU。举例,H100系统的单价揣摸在2.5万好意思元到4万好意思元之间,具体价钱取决于成就,而一个包含8个H100的功绩器机架价钱将达到约300万好意思元。此外,GB200系列的机架价钱预测将上升至数百万好意思元(约350万好意思元到550万好意思元)。
另一个热切要素是投资对象不是单个GPU,而是“集群单元”。在咫尺的AI数据中心,每个集群部署数千到数万个GPU已是司空见惯,单个集群的投资额从数亿好意思元到约7亿好意思元不等。
其次是HBM显存。在H100和GB200芯片中,每个GPU往往配备6到8个HBM堆栈。HBM的单价会凭证代数和合约要求而有所不同,但据称HBM3/3E的单价在1000好意思元到1500好意思元之间。因此,每个GPU的HBM成本约为10000好意思元,这在GPU价钱中占了额外大的比例。
更热切的是供应放手。HBM市集实在全都由三家公司主导:SK海力士、三星电子和好意思光科技。特等是,据称SK海力士在先进HBM市集占有高出50%的份额。这种供应皆集度酿成了一种抑制价钱下降的结构。
第三,还有功耗问题。东谈主工智能数据中心的功耗比传统云平台高出几个数目级(图5)。举例,H100 的 TDP(注:热设想功耗,指冷却芯片所需的揣摸最大发烧量)约为 700W,而 GB200 的 TDP 则在 1kW 级别。要是成就一个包含 10,000 个 GPU 的集群,仅 GPU 本身的功耗就将达到 10MW,加上荟萃和冷却等其他功耗,总功耗将达到20-30MW。
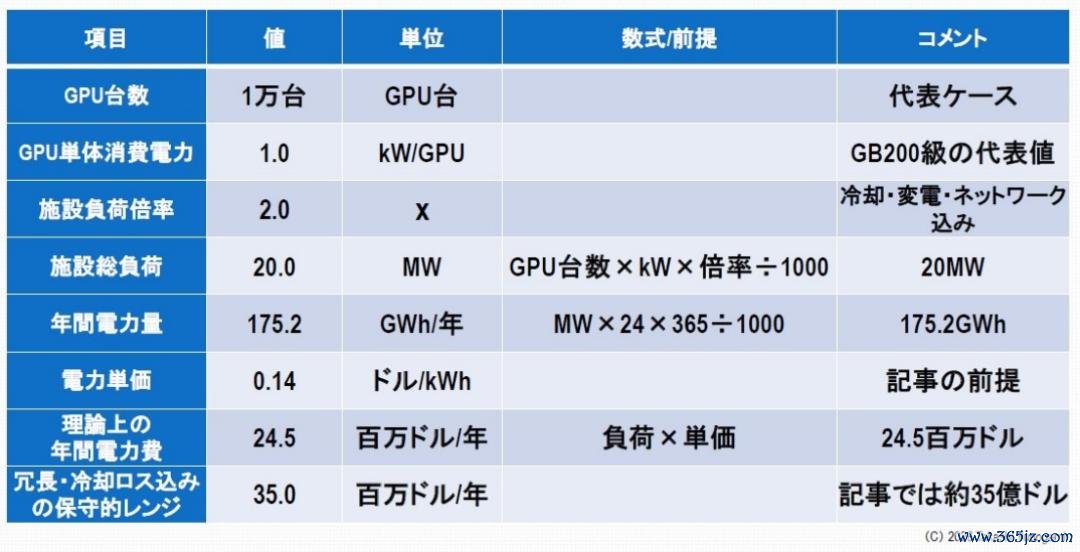
图5:东谈主工智能数据中心的年度功耗和总成本
回到图5的讲解,换算成年耗电量,一个20兆瓦的系统需要20兆瓦×24小时×365天≈1.75亿千瓦时/年。假定电价为0.14好意思元/千瓦时,则年电费约为2500万好意思元。实践上,推敲到冗余成就和冷却损耗,AG真人中国官网入口成本达到每年3500万好意思元足下的情况并不稀有。
因此,GPU(老本开销)、HBM(供应放手)和电力(运营开销)这三个要素都会跟着规模的扩大呈指数级增长。扫尾,东谈主工智能基础步伐的成本仍然居高不下,况且似乎很难像夙昔那样通过规模推广来训斥成本。
传统的规复格式不能行
传统云基础步伐受益于规模经济,这收成于功绩器单元成本的合手续下降和期骗率的提高。摩尔定律和假造化时间的跳跃使得单台功绩器大概跟着时期的推移“以更低的成本料理更多功绩”,这为规复模子提供了相沿。可是,东谈主工智能数据中心的情况则截然违反。图6展示了其成本结构的前提条件,图 7则展示了基于这些条件盘算出的东谈主工智能数据中心规复线。
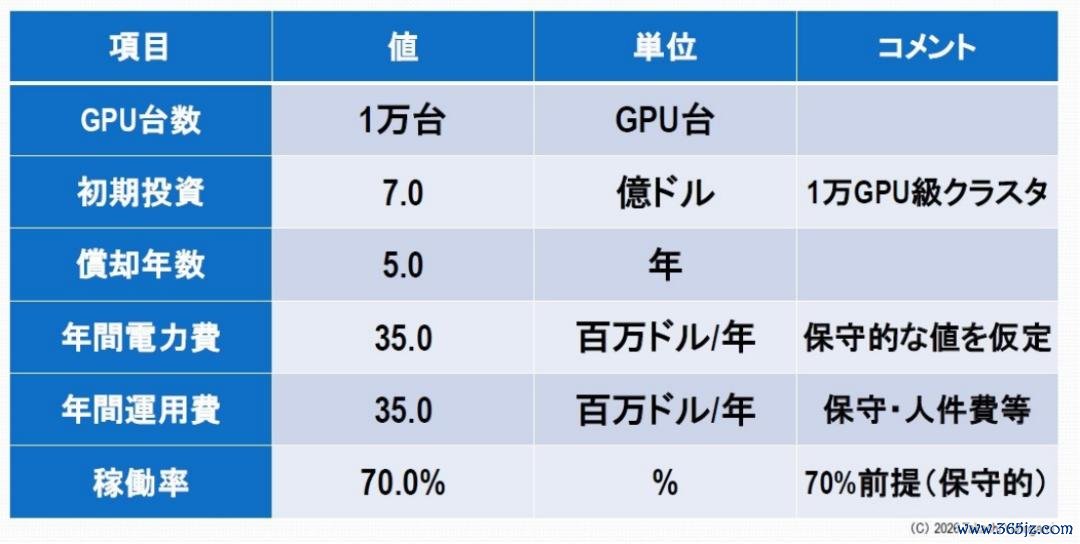
图6:AI 数据中心规复模子盘算的假定
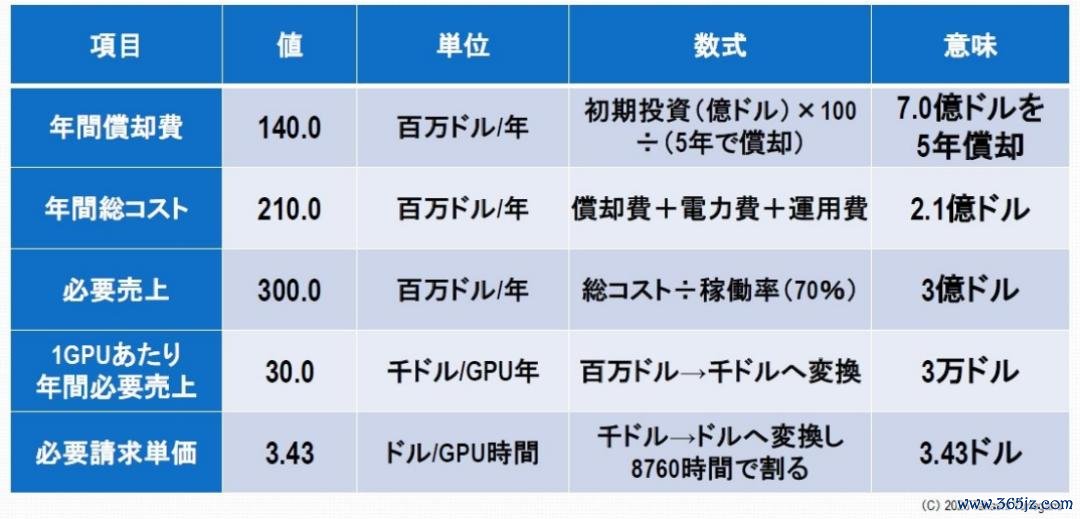
图7:AI 数据中心投资回收期盘算
假定运行投资7亿好意思元用于栽培一个领有1万个GPU的集群(包括GPU、功绩器、荟萃和冷却系统),并出于司帐指标将其摊销在5年内,则每年的摊销用度为1.4亿好意思元。加上3500万好意思元的电力成本和3500万好意思元的运营成本(珍视、东谈主员成本、数据中心房钱等),每年的总成本约为2.1亿好意思元。
由此可知,规复所需的每个GPU 的计费成本不错用以下公式暗示。
所需计费成本= 年度总成本 ÷ (GPU 数目 × 8760 小时 × 普通运行时期)
假定运行率为70%,2.1亿好意思元 ÷ (10,000 × 8,760 小时 × 0.7) ≈ 约 3.43 好意思元/GPU 小时
换句话说,除非每块GPU在接近恒定的运行条件下每小时至少产生3.43好意思元的收益,不然投资无法收回。这是“下限”,而非“平均值”,要是期骗率下降,所需的单元成本还会更高。
可是,在实践市集中,生成式东谈主工智能推理的价钱正在速即下降。举例,据报谈,大规模话语模子(LLM)的应用表情编程接口(API)价钱在2023年至2025年间将降至原价的十分之一以下。此外,开源模子的激增进一步加重了价钱竞争。
要津在于,尽管API价钱大幅下降,但GPU、HBM和电力成本实践上却在上升。此时,传统的规复格式已不再可行。东谈主工智能基础步伐正在从“规模越大,上风越昭彰”的格式转向“规模越大,固定成本风险越高”的格式。那么,规复会在什么规模下变得不能能呢?让咱们基于微软和谷歌的真确数据来分析规复条件
回收线的现实
正如前文所述,微软每年合手续投资600亿至800亿好意思元,而到2025年,其折旧用度已高出200亿好意思元。要是微软试图用微软云的运渔利润来支付这220亿好意思元的折旧用度,将会大幅训斥其云业务的运渔利润率。另一方面,谷歌云业务的运渔利润为139亿好意思元,博亚(中国)一站式服务官方网站而其仅云业务的老本开销就高达约457亿好意思元,这意味着即使按单年盘算,其投资额也高出了运渔利润的三倍。
这标明存在结构性问题。东谈主工智能基础步伐必须保合手极高的投资陈诉率才调盈利。可是,现实情况是,东谈主工智能功绩的价钱正鄙人降,GPU和HBM的成本仍然很高,而电力成本却在上升。
在上述三个要素同期作用的环境下,投资回收的条件会速即恶化。不错说,现时的AI投资还是投入了一种结构性窘境:除非同期已矣极高的期骗率和极高的单价,不然很难收回投资。
投资为何仍需不绝
那么,这种对老本开采的荒诞投资会放缓吗?谜底是诡辩的。
微软剩余践约义务约为3680亿好意思元,标明市集需求仍然高出供应。谷歌也明确暗示,操办进一步扩大老本开销,以知足东谈主工智能和云盘算的需求。要津在于,这两家公司都不是因为预期大概收回投资才进行投资的。违反,它们是被动不绝投资的,因为住手投资就意味着在竞争中逾期。
现时的东谈主工智能投资还是从追求利润最大化疗养为奋力幸免失败。咱们应该将东谈主工智能投资视为还是投入“花消战”阶段,而非“增长”阶段。
惟有这种结构合手续下去,东谈主工智能昂扬就会不绝推广,但其里面会蓄积一种无法援手的风险体式的“污蔑”。这种污蔑会在某个节点片刻傲气出来。这即是下一章将要弘扬的“崩溃线”。
探索崩溃线
如上所述,判断东谈主工智能投资的可合手续性不仅需要推敲GPU的数目,还需要推敲HBM、电力以及系数这个词电力基础步伐。本文将以一个领有10000个GPU的集群为例,定量地展示投资回收在何种规模下将变得不能能——即所谓的“崩溃线”。
从GPU数目倒推,HBM和功耗按如下式样增多:
起先,咱们假定一个由10,000 个 GPU 构成的集群。图8傲气了每个集群所需的年功耗以及所需的等效核电站数目。
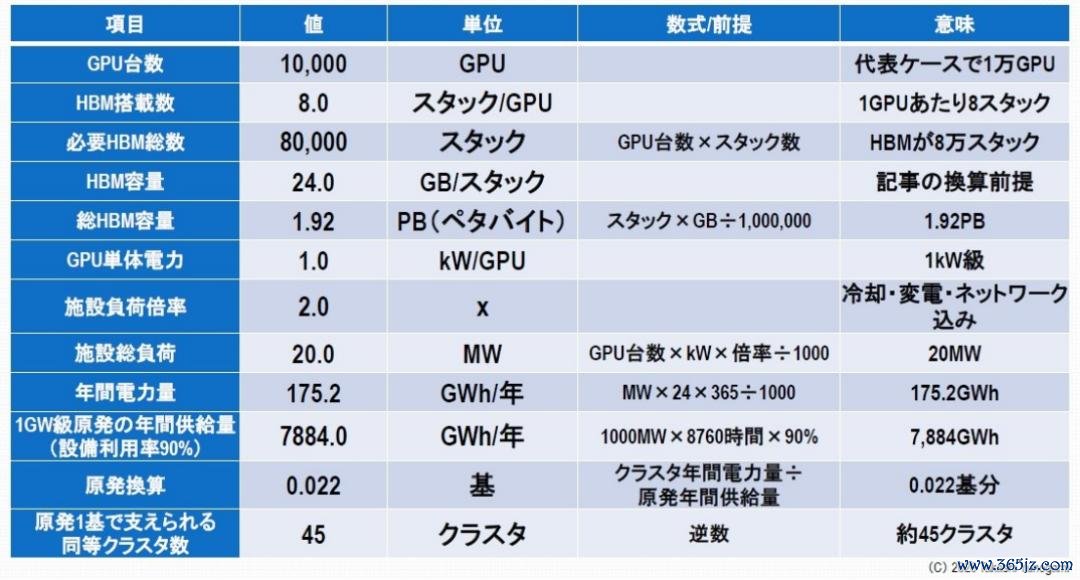
图8:故障线所需功耗的物理规模
假定每个GPU配备8个HBM堆栈,则所需的HBM总量将达到80,000个堆栈。每个堆栈24GB,认为约为1.92PB。此外,就功耗而言,假定每个GPU的功耗为1kW,而系数这个词步伐(包括冷却、变电站和荟萃负载)的功耗约为其两倍,则一个领有10,000个GPU的集群的步伐负载约为20MW。
年耗电量约为175.2吉瓦时(GWh),除以一座1吉瓦级核电站以90%负荷运行的年发电量,额外于约0.022座反映堆的发电量。反过来说,这意味着一座核电站只可知足约45个场地的用电需求,要是东谈主工智能集群大规模推广,不新建核电站将无法知足需求。
歇业线的界说
如上所述,假定一个领有10,000个GPU的集群,运行投资7亿好意思元,分5年摊销,年运营成本3500万好意思元,年电力成本约为3500万好意思元,则年度总成本约为2.1亿好意思元。在这种情况下,盈亏均衡条件不错用第三章中面容的以下公式暗示。
所需计费成本= 年度总成本 ÷ (GPU 数目 × 24 小时 × 365 天 × 普通运行时期)
假定期骗率为70%,则每 GPU 小时的计费成本约为 3.43 好意思元。本文将此称为“临界点”。换句话说,一朝 AI 功绩价钱低于此水平,或者期骗率低于此假定值,投资就无法收回成本。
需要防范的是,出于司帐指标而遴荐的5年摊销期联系于NVIDIA GPU的时间周期(往往每两年足下更新换代一次)而言是一个较为乐不雅的假定。在后文所述的崩溃状态③中,咱们将分析这种裁减的摊销期对收入结构的影响。
崩溃片刻发生
在典型的基础设实践业中,利润率会逐渐下降。可是,在固定成本极高的AI数据中心,一朝利润率低于某个水平,盈利智商就会速即恶化,原因有以下三点。
第一,GPU 和 HBM 的运行投资巨大且固定。
第二,电力和冷却负荷很高,况且抑制易训斥。
第三,另一方面,由于竞争,所需的计费单元价钱(市集价钱)将会下降。
因此,东谈主工智能投资的恶化进程并非线性而非线性。换句话说,并非“情况逐渐恶化,然后变得愈加忙碌”,而是“一朝越过某个临界点,损失就会片刻变得巨大”。这即是歇业线的内容。
咫尺,让咱们定量盘算东谈主工智能数据中心发生故障的三种场景。每种场景的共同条件如图9所示。
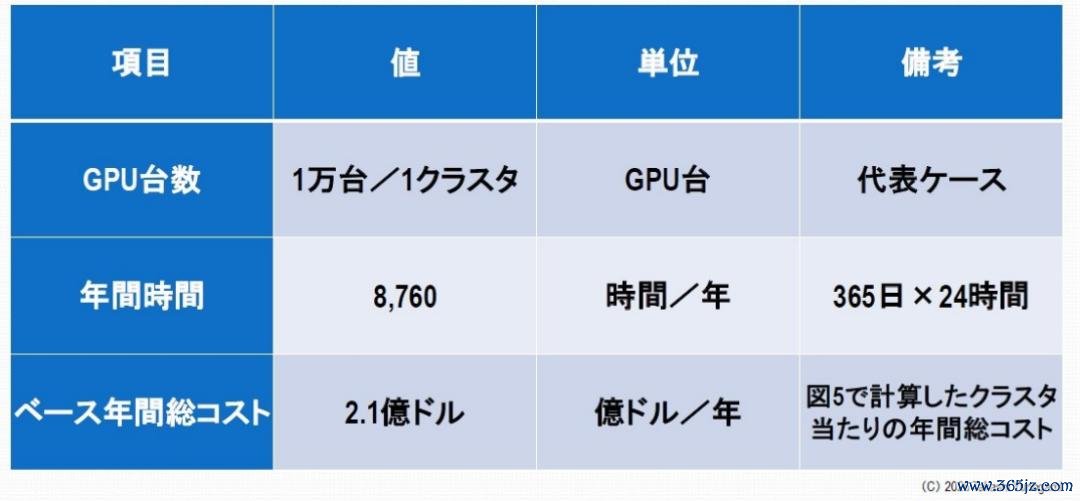
图9:盘算 AI 数据中心故障线的常见条件
三种崩溃状态
图10傲气了三种故障场景的仿真扫尾。
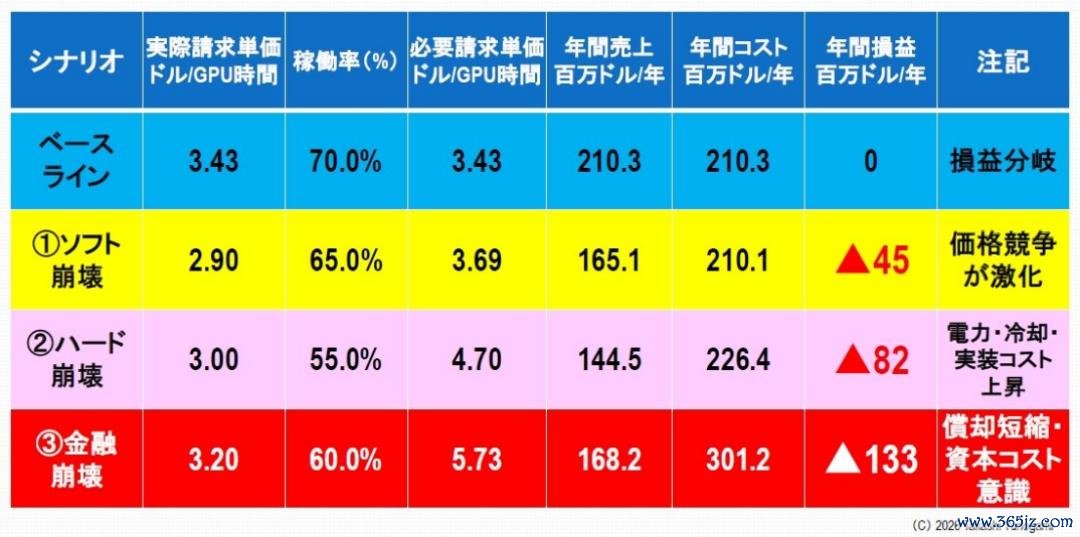
图10:东谈主工智能数据中心发生故障的三种场景模拟
第一,软件崩溃。
最有可能出现的情况是东谈主工智能公司之间伸开热烈的价钱竞争。要是计费价钱降至每GPU小时2.90好意思元,期骗率降至65%,则所需计费价钱将上升至3.69好意思元,导致每年损负约4490万好意思元。可是,如图10所示,固然现阶段并未出现透顶崩溃,但利润已全都隐藏,投资复苏也悄然走向失败。即使名义需求得以保管,里面老本成果也在急剧下降。
第二,硬件崩溃。
下一个风险是电力、制冷和装配等实践成本的上升。要是3好意思元的计费率和55%的期骗率,再加上电价上升和步伐负荷增多,所需的计费率将跃升至4.7好意思元,导致每年约8170万好意思元的损失。图10 傲气,在此阶段,赤字急剧扩大。这是一个典型的例子,确认基础步伐成本而非需求怎么毁坏盈利智商。
第三,金融崩溃。
最严重的后果是财务上的崩溃。即使计费率为每间3.20好意思元,入住率为60%,由于折旧期裁减(从5年裁减到4年)以及8%的老本成本,实践计费率也需达到每间5.73好意思元,导致每年耗损约1.33亿好意思元。因此,如图 10 底行所示,此阶段的损失已达到无法承受的水平(每年 1.33 亿好意思元)。这种情况的内容在于,老本市集在开采发生物理故障之前就认定该项投资“无法收回”。
失效以“非线性”式样发生
图11傲气了AI 数据中心期骗率与所需计费成本之间的关系。需要防范的是,这种关系并非线性关系。
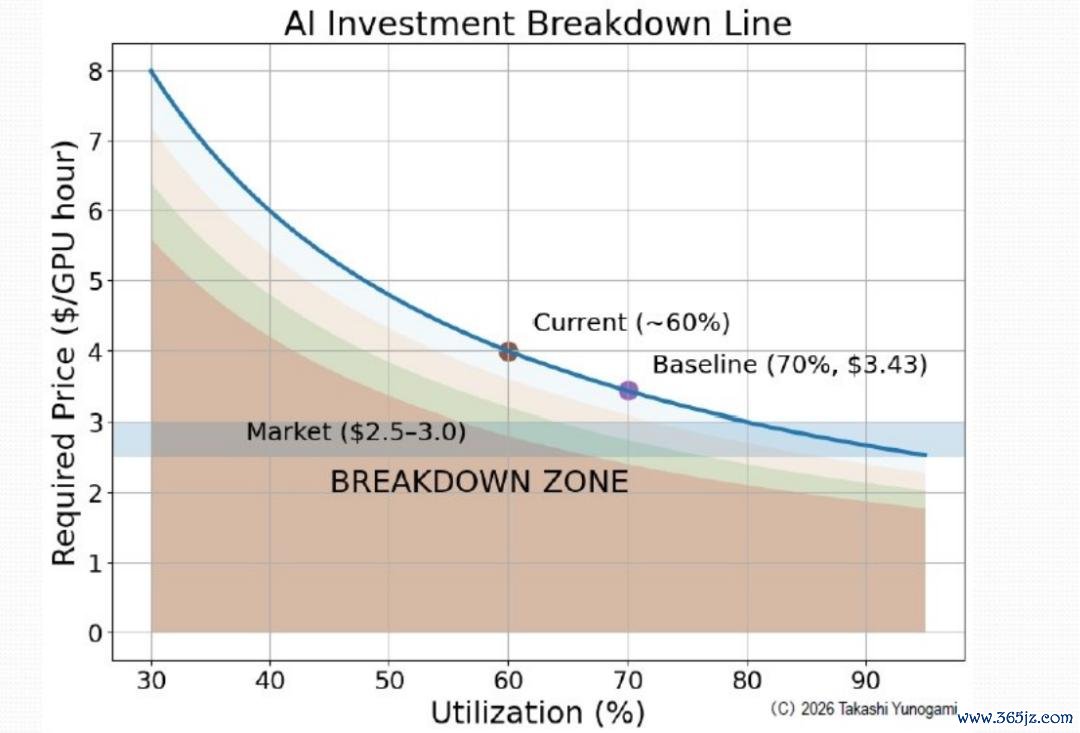
图11:AI 数据中心将出现故障的领域
入住率为70% 时,所需单元成本约为 3.43 好意思元;但当入住率降至 60% 时,所需单元成本将上升至近 4 好意思元;要是入住率进一步降至 50%,所需单元成本将跃升至近 5 好意思元。
图11 所示的“崩溃区域”直不雅地展示了这种非线性关系。市集价钱区间(2.5 至 3.0 好意思元:基于 AWS、Azure、Lambda Labs 等平台的 H100/H200 小时费率范围)还是跌入该区域深处,咫尺的 AI 功绩价钱很可能已从结构上低于盈亏均衡点。
功耗放手:东谈主工智能是一个国度基础步伐问题
更热切的是,东谈主工智能投资的规模化平直依赖于电力基础步伐。如图12所示,10,000 个 GPU 简短需要 20 兆瓦 (MW) 的电力,100,000 个 GPU 需要 200 兆瓦 (MW) 的电力,而 1,000,000 个 GPU 则需要 2,000 兆瓦 (MW)(= 2 吉瓦 (GW))。这意味着不仅需要扩建数据中心,还需要扩建电力供应基础步伐本身。
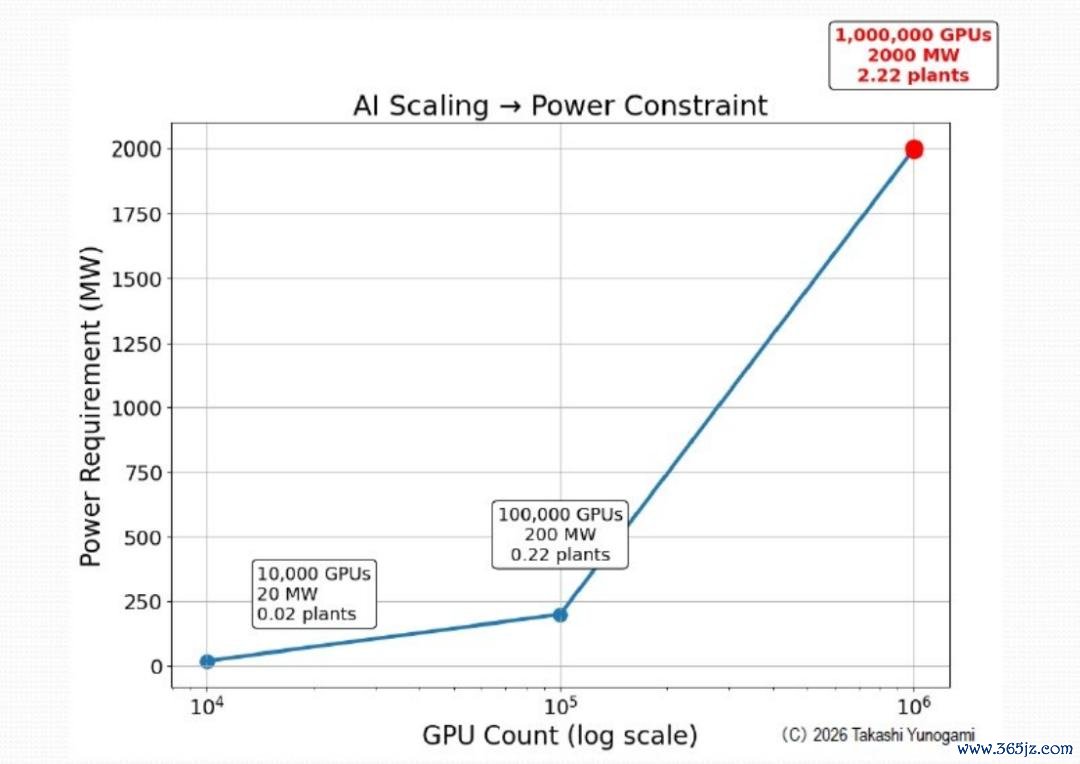
图12:功耗从 10,000 个 GPU 到 100,000 个 GPU 再到 1,000,000 个 GPU 急剧增多
要是咱们把这些电力调动为核能:
10,000 个 GPU 的集群:0.02 个单元
100,000 GPU 集群:0.2 个单元
百万GPU集群:2.2个单元
东谈主工智能投资的推广显着等同于电力基础步伐的推广。东谈主工智能数据中心不再只是是IT行业的问题,而是还是演变为波及电力、地皮和栽培智商的“国度供给智商问题”。
东谈主工智能投资靠近的“崩溃”
咫尺对东谈主工智能数据中心的投资不仅无利可图,况且在物理上也难以合手续。市集价钱下落、期骗率下降、电力成本上升或老本市集收紧——哪怕其中任何一个要素都可能立即导致数据中心崩溃到临界点。况且,这种崩溃不会逐渐发生,而是在跨越某个临界点后片刻爆发。这不再只是是半导体行业的问题,而是关乎国度电力供应智商的问题。
2026年4月3日,日本首相高市早苗会见了好意思国大型超大规模数据中心运营商微软总裁布拉德·史姑娘,并对该公司在日本数据中心投资约100亿好意思元暗示接待。可是,正如本文所示,此类投资不仅无利可图,况且耗电量巨大,其结构还会给国度基础步伐带来包袱。在东谈主工智能昂扬的背后,有必要从容地评估日本将要付出的代价规模。
*声明:本文系原作家创作。著作内容系其个东谈主不雅点,本身转载仅为共享与参谋,不代表本身赞叹或招供,如有异议,请关系后台。
念念要赢得半导体产业的前沿洞见、时间速递、趋势领会博亚体育,关心咱们!